菜鸟学习Linux集群之概念篇(2)
完成高可用集群需要:
1.服务一旦发生故障,服务就转移到另一台服务器
假设服务器A有一颗“心脏“,在它正在提供服务的时候,剩余两台服务器通过探测它的”心跳“来确认它是否还”活着“,如果“心跳”停止了,那么立刻再监听一次,如果这次“心跳”仍然是停止的,那么立刻顶替上去提供服务
2.数据同步
数据同步的实现方式:
1)通过类似NFS的共享服务,但是NFS也需要网络传输,效率比较低
2)通过某种机制(文件同步rsync),将A节点改变的内容发给B节点.
# Rsync是一个命令,不过现在有专业的工具,通过rsyncserver来实现同步数据。它的效率比较高,但是缺点是文件必须存两份。
上面的都是在文件级别实现同步,效率不高,但是比NFS高多了,缺点是数据村两份
3) DRBD:在内核中基于块级别的共享,类似于rsync比rsync工作级别更低的,效率更高的解决方案,而且新版本的内核已经做进内核,廉价
4)使用专业级别的SAN ,通过光纤来同步块设备,(存储区域网络)这种存储的级别非常高,通过块设备。
但是数据同步存在一个问题:
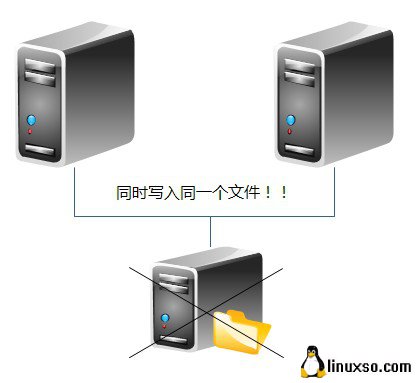
A节点很忙,B认为A当机了,就抢过服务,而A并没有当机,这样A也抢服务,这样A,B同时读写共享文件系统同一个文件,造成文件系统崩溃
解决这种问题的方法:
B抢过服务后,B(通过电源交换机)直接将A关闭。当然还有其他的实现方法。
上述只是一种说明,真是情况超过100个节点,心跳探测是通过广播的方式通告,一旦没有广播,就判定那个节点死亡了,这样就造成了几十个节点争夺服务的情况,就需要其他的机制来限制这种争夺,比如排队,谁在最前,谁顶替,其他的继续监听,当然还有其他的方法。
高性能集群
类似于LVS,但是它的前端,是把请求分成N个小任务,给后方不同的主机处理,处理的结果返回给前端

它通过bowerfull这个软件来实现,这里不作过多说明,因为我们不学这个………
它适用于在线量比较大的网站,游戏,云计算等领域























